Initially, I wanted this post to focus solely on metrics in machine learning. However, the concept of metrics is far more universal, and it doesn’t make sense to treat it as an isolated problem. This is more of a philosophical post, the ultimate goal is to make you think and reflect.
We live surrounded by metrics: grades from teachers, performance reviews from employers, publication counts in academia, FLOPs in computing, ELO in chess, salary, IQ for intelligence, movie ratings on IMDB, book ratings on Goodreads, stars/reviews on Amazon, election results in democracies, F1 score in machine learning, GDP for countries, EBITDA in finance, likes/followers on Instagram, time spent on TikTok for content recommendation algorithms, etc.
In most cases, these metrics try to summarize a complex system with a single number, which is often inaccurate. For example, a well-behaved metric should be comparable, meaning:
if A > B and B > C, then A > C
In mathematics, this property is called transitivity. However, in real life, this almost never holds; there are usually trade-offs.
In some cases, choosing the wrong metrics can lead to catastrophic failure (as we’ll see with some examples). I want to argue that choosing the right metrics is as important as solving the problem itself (just as asking the right questions is as important as answering them).
Egregious examples of bad metrics
People coined the term enshitification [8] to describe when a system becomes corrupted and degraded due to poor incentives; a phenomenon we’ve seen in many companies. The most famous example is Airbnb: it began as an alternative to hotels, where a host might share a room and both host and guest benefited for a modest price. Today, Airbnb prices are often similar to hotels, and the platform has contributed to gentrification (and toxic tourism) in many European cities [9].
Here are several other examples of bad metrics and perverse incentives:
p-hacking in statistics: In statistics, it’s common to use p-values to describe confidence in the results of a test. The standard threshold for statistical significance is 0.05. This has led many researchers to aim for this arbitrary threshold at all costs. We’ve seen numerous retractions over the years, and countless others likely go unnoticed [2].
overfitting in machine learning: Over the years, there have been many examples of data leaking—training the model using the test set split [3]. Also, when your only goal is to optimize a single metric, you may overfit to that task, even without using the test set, resulting in a model that is virtually useless.
Cooking the books in planned economies: In the 20th century, during the USSR under Khrushchev, company and factory leaders often manipulated production data or falsified results to appear more successful than they actually were. Because the Soviet economic system rewarded meeting targets rather than genuine efficiency or quality, managers frequently inflated numbers, hid waste, or produced useless goods just to report success. This, among other causes, contributed to the fall of the USSR.
Incentives tied to management: CEOs were often paid bonuses based on quarterly earnings. As a result, many prioritized short-term wins over long-term health, using financial tricks that ultimately led to poor company performance.
In-class assessment: Although the main goal of school is learning, it’s usually measured through exams or projects. Many people practice the art of cheating. Another form of “cheating” is memorizing instead of understanding, which leads to poor learning and forgetting concepts after the exam.
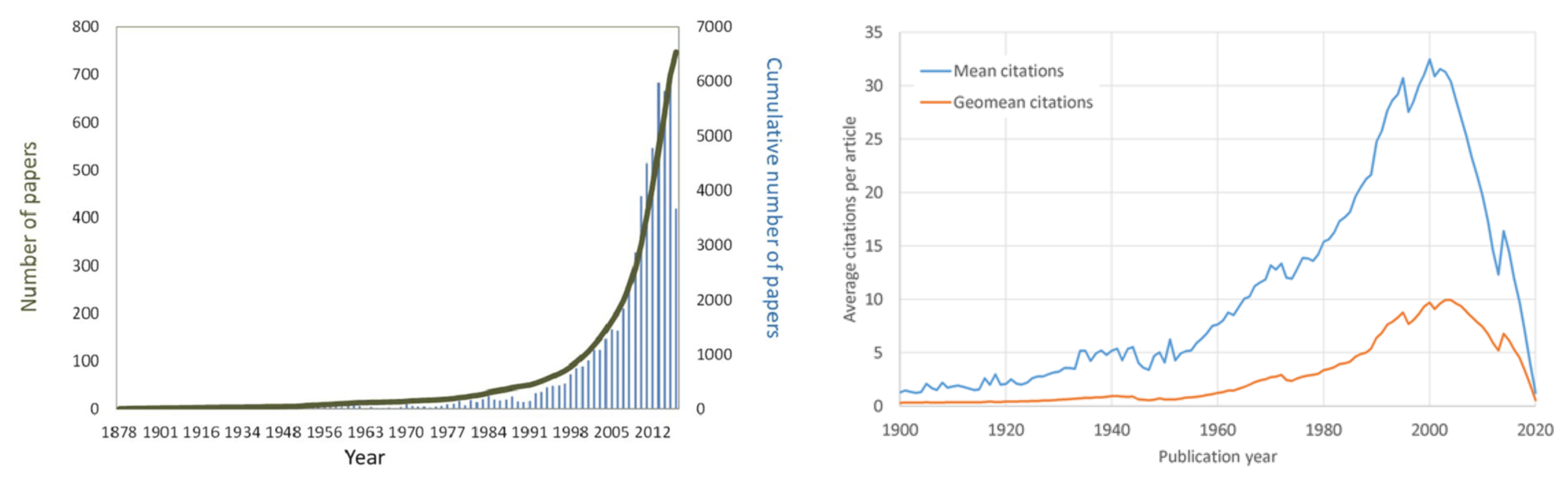
Academia: The most important metric for researchers is the number of publications and citations. This has created a major misalignment of goals, and today, there’s a broken culture where publishing many and fast is the norm [[4]]. The following graphs show the evolution of the number of publications and average citations per paper [6, 7]. It seems we are producing so much information that no one reads…
Private healthcare: When the goal of a hospital is not to cure the patient but to make money, it can create perverse incentives: overcharging, prolonging treatment, and offering expensive solutions to simple or non-existent problems. I highly recommend this video [1]. The same happens in education systems.
Democracy: Political parties only care about the results of the next elections and not the long-term prosperity or planning of the city. Unaffordability of housing, short-term thinking, etc.
These are a few examples I could come up with, but I think anyone can see the pattern and come up with others.
If we look at the root problem, we see it’s a recurring issue throughout history—a byproduct of misaligned incentives. Sometimes, taking your eyes off the spreadsheet and reflecting can help solve these issues. One of the most famous quotes in investing highlights the importance of this concept:
“Show me the incentive and I will show you the outcome”
— Charlie Munger
We may think this is something new, but it’s far from the truth. For example, in the 15th century, pirates and marines were not taught how to swim to prevent them from running away in battle. There are cases of positive incentives as well: during ancient Rome, soldiers were paid directly from war spoils, and the same happened with Hannibal in the Second Punic War. In the Iberian Peninsula during the Reconquista, peasants were encouraged to settle these dangerous frontier lands by offering tax exemptions and other benefits. More recently, people thought the invention of the atomic bomb would bring about the end of the world; however, we saw the opposite—countries are disincentivized to attack others holding nuclear arsenals.
This last example also relates to the well-known Prisoner’s Dilemma in game theory, where we study optimal behaviour given a set of rules and incentives.
We’ve seen similar questions arise in AI safety and alignment, where people try to set the right incentives for AI to safeguard the common good. However, it remains an open question whether intelligence can, in principle, be combined with any kind of goal, allowing scientists to shape AI incentives. This is known as the Orthogonality Thesis [17]:
“Are Intelligence and final goals (values, objectives) orthogonal?”
The most difficult part of Reinforcement Learning is usually setting the reward (incentive) correctly. This has been one of the field’s most important challenges, and people still struggle with how to set the reward during training. Setting a difficult environment hinders training, and choosing a single reward can lead to reward hacking [16].
I think of an incentive like a second derivative: it’s a force that moves people’s interests in one direction. At first, people barely notice it, but the consequences become clear over time. Or, in mathematical terms, using the Taylor expansion:
$$f(t) = f(0) + tf'(0) + \frac{t^2}{2}f''(0) + \mathcal{O}(t^3)$$When $t$ is small, higher-order terms are negligible; as $t$ grows, the influence of the second derivative and beyond can dominate.
Designing systems that remain robust over time is often difficult. In the long run, benchmarks and incentives can be gamed in unanticipated ways. Goodhart’s law captures this:
“When a measure becomes a target, it ceases to be a good measure.”
Corrosion is often slow and unnoticed until it’s significant. That said, I don’t think corruption is inevitable: well-designed metrics and adaptive governance can lead to stable equilibria. We need to be deliberate about which metrics we choose, not leave results to chance, and stay ready to adjust them when incentives produce unintended consequences.
How can we apply this to our daily life?
Metrics influence everyone, including you. Ask yourself which artificial metrics shape your decisions, and whether they reflect your values.
The first thing that comes to mind is how each of us measures success: Are you guided by money and status, or by internal goals? It’s worth aligning external measures with personal values rather than blindly chasing others’ expectations.

And what about machine learning?
Even simple loss functions such as Mean Squared Error (MSE) and Mean Absolute Error (MAE) have different properties: MAE promotes sparsity and is more robust to outliers, while MSE penalizes large errors more heavily and is differentiable everywhere. Choosing a metric affects model behaviour.
More importantly, the dataset and benchmarks you use matter. For example, in computer vision, the ImageNet dataset helped spark the AI revolution; similarly, progress in NLP has been accelerated by high-quality, diverse benchmarks [10]. Good benchmarks encourage generalization rather than overfitting to a single metric. If one metric is insufficient, use multiple: confusion matrices, precision/recall, calibration, and task-specific measures provide a richer picture than a single scalar.
Choosing the right metric in ML is very important, but having access to the right dataset and benchmark is crucial and often undervalued. The long-term impact of benchmarking is almost always unnoticed. The competition that sparked the modern AI revolution began with the ImageNet dataset. Recent advances in NLP are partly due to high-quality, well-curated, and diverse benchmarks. The abundance and variety of benchmarks in NLP completely overshadow other fields [10]. This has allowed teams to focus on generalization rather than optimizing a single benchmark. It almost seems trivial to say, but if a single metric is insufficient, use more than one. For example, use the confusion matrix rather than a single-number score.
One historical reason robotics underperformed compared to other fields was its poor benchmarks. However, we’ve seen a lot of progress lately with new environments and the push for RL [11, 14, 15]. In AI for materials and drug discovery, we are seeing a golden age as well [12, 13].
References
[1] “I Was An MIT Educated Neurosurgeon Now I’m Unemployed And Alone In The Mountains How Did I Get Here?” https://www.youtube.com/watch?v=25LUF8GmbFU&t
[2] p-hacking: https://en.wikipedia.org/wiki/Data_dredging
[3] data leaking: https://en.wikipedia.org/wiki/Leakage_(machine_learning)
[4] “Scientific publishing is broken” https://www.theguardian.com/science/2025/jul/13/quality-of-scientific-papers-questioned-as-academics-overwhelmed-by-the-millions-published
[5] “The misalignment of incentives in academic publishing and implications for journal reform” https://www.pnas.org/doi/10.1073/pnas.2401231121
[6] Monteiro, Maria & Séneca, Joana & Magalhães, Catarina. (2014). The History of Aerobic Ammonia Oxidizers: from the First Discoveries to Today. Journal of microbiology (Seoul, Korea). 52. 537-47. 10.1007/s12275-014-4114-0.
[7] Mike Thelwall, Pardeep Sud; Scopus 1900–2020: Growth in articles, abstracts, countries, fields, and journals. Quantitative Science Studies 2022; 3 (1): 37–50. doi: https://doi.org/10.1162/qss_a_00177
[8] https://en.wikipedia.org/wiki/Enshittification
[9] Rabiei-Dastjerdi, Hamidreza, Gavin McArdle, and William Hynes. “Which came first, the gentrification or the Airbnb? Identifying spatial patterns of neighbourhood change using Airbnb data.” Habitat International 125 (2022): 102582.
[10] https://main--dasarpai.netlify.app/dsblog/nlp-benchmarks1/
[11] https://github.com/newton-physics/newton
[12] https://ai.meta.com/research/publications/open-molecular-crystals-2025-omc25-dataset-and-models/
[13] https://moleculenet.org/datasets-1
[14] https://gymnasium.farama.org/
[15] Kaup, Michael, Cornelius Wolff, Hyerim Hwang, Julius Mayer, and Elia Bruni. “A review of nine physics engines for reinforcement learning research.” arXiv preprint arXiv:2407.08590 (2024).